I spent this morning gathering performance data for all of our major supported devices. The results are very interesting.
First a note on methodology, these tests where intentionally performed against a distant (70ms) exit server and against real internet targets. In terms of pure iperf performance these devices can usually do about ~30% more, but I wanted to get realistic usage numbers. Including things like TCP window scaling thanks to the high latency and distance. What’s not realistic about this test is that mesh links are perfect (Ethernet cables). I wanted to inspect the software stack that’s under direct our control for problems before diving into antenna tuning.
The results are really interesting. Latency wise performance is flawless across the board, less than half a ms additional latency per hop, meaning video calls or live streaming will continue to be viable even deep into the network.
In terms of throughput loss to meshing things are also pretty positive. When meshing with a higher performance gateway devices nodes actually saw throughput increase which says good things about our packet scheduling and network design. On the other hand deeper connections of identical devices must suffer the rules of queueing theory. Throughput has to go down as the chain increases in length. At a rate of about 5-10% per hop currently from current tests, but these aren’t very reliable to extrapolate form.
The absolute value of mesh throughput is a little more complicated and related to Wireguard encryption performance and other device properties. Lets compare our two highest performance devices. The EdgerouterX using a MT7621 and the Turris Omnia using a Armada 38x. You may notice that the Omnia has about double the cpu clock speed and about double the performance.
While this is intuitively ok, the reality is that it shouldn’t be the case. The Armada has a L2 cache (L1 cache specs are the same on both devices) and ARM is typically considered to have a higher IPC (instructions per clock) execution rate. It’s hard to narrow down what’s causing what here, my hunch is memory speed and lack of DMA to make copying traffic around efficient, I should probably do some cache miss stats on the Omnia before reaching further conclusions.
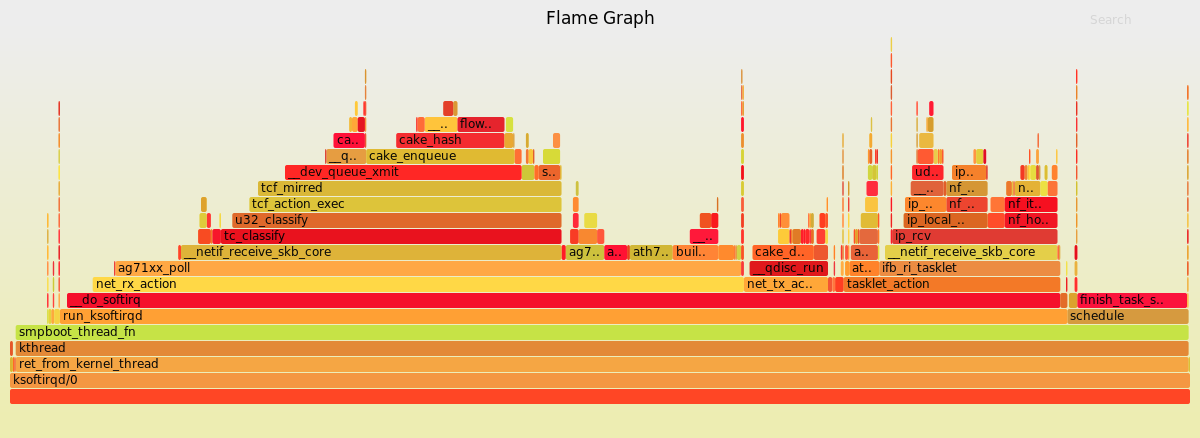
A supporting note is that on the n750 35% of the total cpu load is in sirq AKA copying data off of the nic and into memory. This could indicate a lack of DMA (direct memory access) where higher frequencies would directly assist in memory bound workloads.
So the results for the Armor Z2 set a new record for disappointing. The big question is why? In every objective measure the integrated processor is better than the one in the Omnia, which demonstrates high performance.
I’m leaning to an issue with the port, and I’ll have to dig more deeply to see if I can find exactly why. Both targets use Wireguard’s NEON optimization. Next up on my to test list are the following devices.
I’m most excited with the gil.inet while I generally haven’t found their hardware to be the best in the world it’s always been well done and easy to work with. A quad core arm gives me high hopes on mesh performance.
@jkilpatr have you tried reaching out to the batman adv folks about this? Their protocol necessitates processing on a route that possibly skips the hardware optimizations etc so maybe they have experienced similar issues
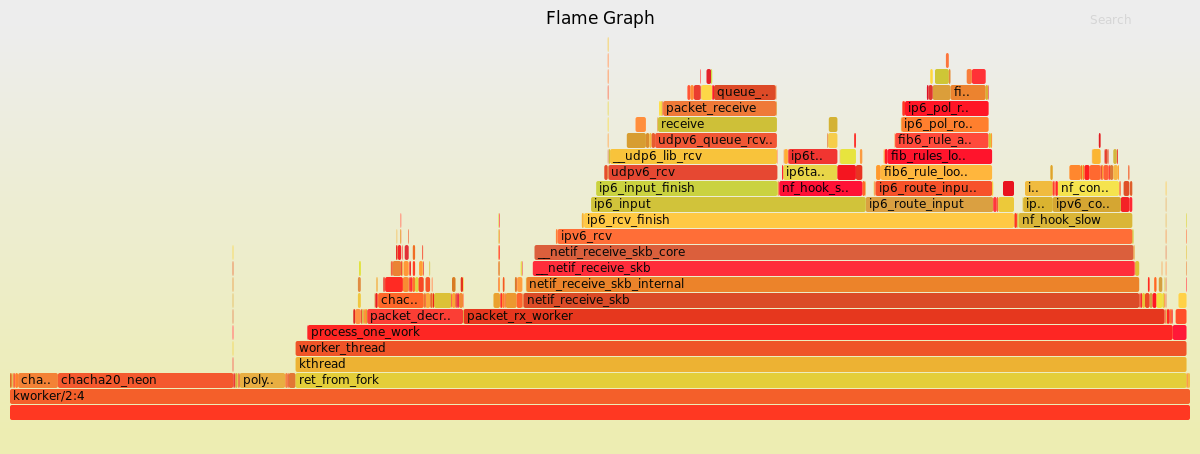
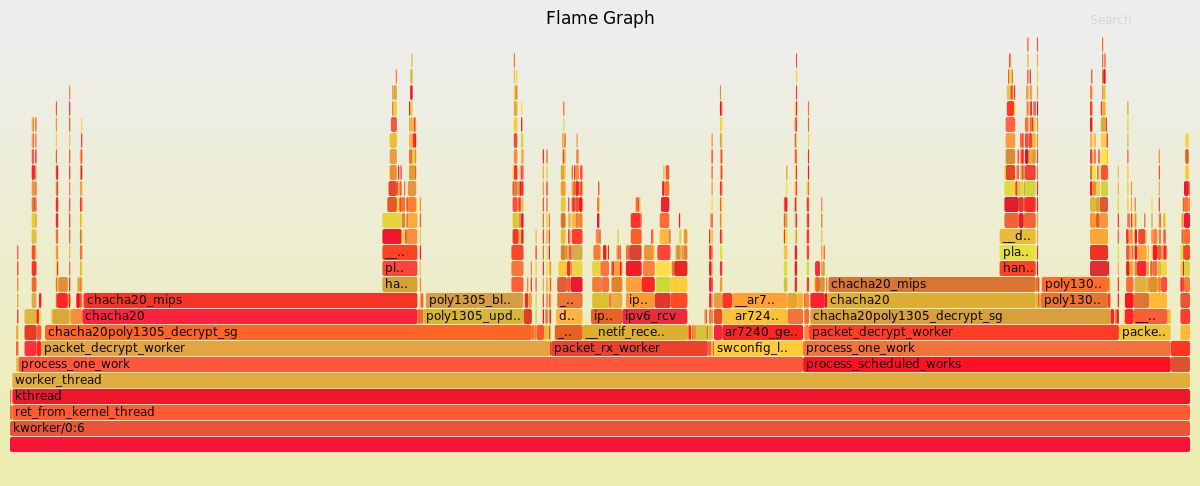
Now this is really interesting, see that little block over in the starting corner? that’s all the decryption work, you see the big stack on the right, that’s our iptables rules.
But now this one totally contradicts that, is Arm Neon that much more efficient? But in general it seems we’re not restricted by the performance of these kworkers at all, so do we even care? It seems that LEDE’s lack of hardware offload in most cases causes most of our performance problems. Our entire encryption stack is usually only 5-10% overhead compared to raw LEDE. Guess it’s my bad for not getting a good baseline.
that last one is the sysirq thread, so there’s no wireguard there.
The middle one is the n600 and I’m confused as to why wireguard dominates there versus ip6 tables, iptables is there but is much much faster by comparison. Maybe the arm Neon implementation of wireguard is just that much faster? Maybe my random selection of kthreads caused sample bias?
managed to monkey patch in Qualcom Fastpath offload suppport on the n750, no change from the 30mbps tcp perf we normally see (strangely udp perf sucks no matter what, in a reversal of the norm). Rumor on the forums is that you can get an erx to go from 100/100 shaped nat speed to 500/500 with fastpath support, but I can’t find a simple patch like I could for the n750 overall I don’t think it’s worth the current time investment. I’ll come back to it when we’re really needing the speedboost. Maybe then I can take the time to upstream it proper.